Office Document Finder - эффективный поиск в документах
 Мне практически ежедневно приходится что-то искать среди документов: прежде всего среди файлов Word, реже - в файлах электронных таблиц и совсем редко - в файлах презентаций.
Мне практически ежедневно приходится что-то искать среди документов: прежде всего среди файлов Word, реже - в файлах электронных таблиц и совсем редко - в файлах презентаций.
Но вот где еще часто что-то приходится искать, так это в документах PDF, а там с поиском все совсем нетривиально: PDF - это векторный формат, он может содержать и текст, и изображения, также в тексте нередко попадаются разрывы в середине слов, что сильно осложняет поиск.
В операционной системе Windows есть свой встроенный поиск, но он достаточно примитивный и пользоваться им можно только для самых простейших задач.
Поиск операционной системы Windows 10
Я пробовал несколько специальных программ продвинутого поиска, без которых мне не обойтись, и у всех них есть свои достоинства и недостатки.
Некоторое время назад разработчики Office Document Finder предложили мне познакомиться с их продуктом. Эта система работает под Windows, Mac и Linux, поддерживает облачный доступ, работу на мобильных устройствах и через браузер.
Система мощная, интересная, я теперь ее сам использую практически ежедневно, а кроме того, оказалось, что разработчики прислушиваются к пожеланиям пользователей и быстро вносят в систему какие-то дополнения.
Сразу предупреждаю - система не бесплатная. Для бесплатного ознакомления там дается целый месяц, причем функциональность ничем не ограничена, и если по результатам тестового периода вы решите приобрести лицензию, то она приобретается на год. Персональная лицензия на год стоит 2400 рублей (на мой взгляд, вполне разумная цена, учитывая возможности), также есть бизнес-лицензия на 10 пользователей (на каждого получится 1700 рублей в год) и корпоративная лицензия на 100 пользователей (790 рублей за пользователя).
Конечно, обычному домашнему пользователю такая система не нужна: его, скорее всего, устроит встроенная система поиска Windows. Но есть целый ряд пользователей - так сказать, домашне-профессиональных, то есть тех, кто работает дома и которым нужны значительно более продвинутые инструменты быстрого поиска нужной информации. Ну и заметим, что за период коронавирусного дурдома, когда многих людей перевели работать на удаленке, количество подобных пользователей увеличилось на порядки.
А теперь давайте смотреть, какие возможности предоставляет Office Document Finder.
Работа приложения
Соответствующее приложение (Windows, Mac, Linux) скачивается со страницы системы и устанавливается.
При первом запуске (я рассматриваю приложение под Windows) появляется вот такое окно.
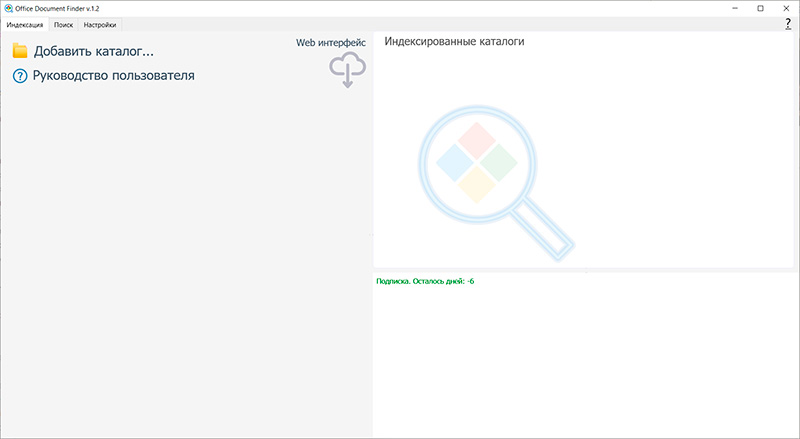
Там прежде всего нужно добавить каталог для индексирования - основную папку, в которой хранятся все ваши документы (обычно это папка "Мои документы"). Если у вас документы хранятся в разных папках, то их нужно по очереди добавить для индексирования.
С сетевыми дисками система работает точно так же, как и с локальными: для индексации можно добавлять папки, расположенные на дисках локальной сети.
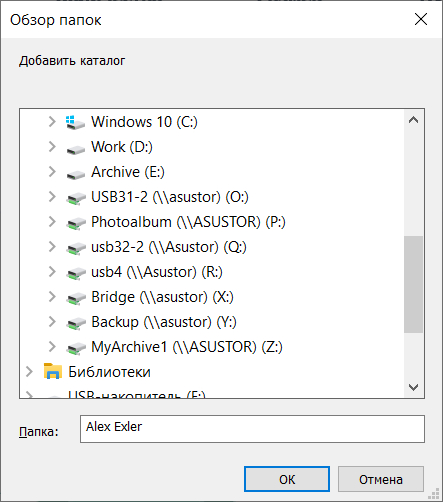
В меню сверху есть раздел "Настройки", там можно выбрать, какие именно виды документов нужно индексировать. Также там задаются частота обновления индекса, возможность распознавания текста на изображениях (например, в PDF-файлах) и показ облака тегов документа. (Внимание: распознавание текста на изображениях очень сильно замедляет скорость индексации!)
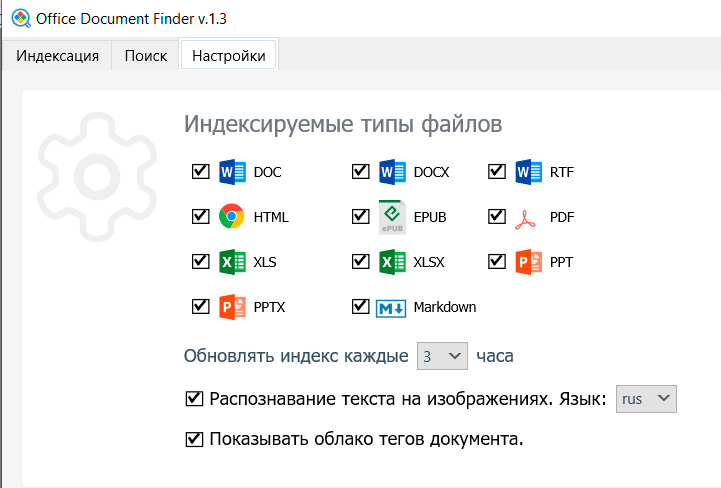
После обработки программа покажет вам соответствующую статистику: сколько каких документов проиндексировано, какой размер тех или иных групп документов. Обратите внимание на то, что программа также показывает обнаруженные дубликаты (полностью идентичные файлы), они в индексацию не включаются.
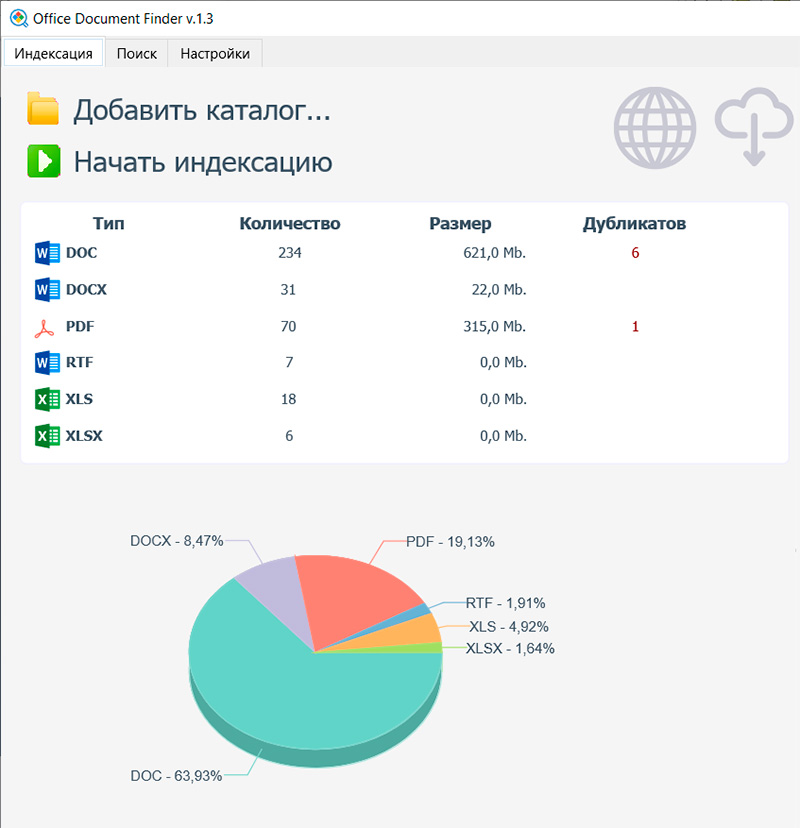
Если вы добавили в папку какие-то новые документы и вам нужно, чтобы они сразу попали в поиск, то нужно просто нажать кнопку "Начать индексацию": информация о процессе индексирования будет выводиться в приложении.
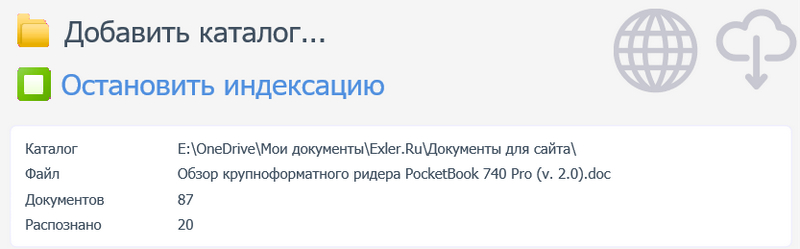
Раздел меню "Поиск". Слева сверху - строка для поиска. Под ней - виды документов (те, по которым ведется поиск, выделены жирным шрифтом: если какой-то вид нужно убрать, то по нему нужно просто щелкнуть мышкой), критерий отбора (все слова или любое слово из строки поиска), вид сортировки выдаваемых документов.
Строка ниже содержит разделы: сами документы, найденные фрагменты (вхождения поисковых слов), оглавление (не для всех документов) и список аналогичных (похожих) документов.
В конце строки значок переключения режима просмотра от полноразмерного к миниатюрам.
В окне справа - делается просмотр документа, там присутствуют пиктограммы масштабирования.
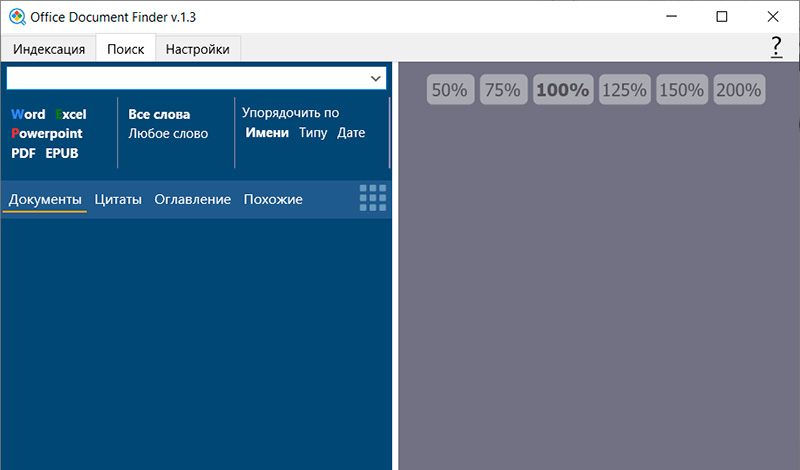
Вводим нужную строку для поиска. Система сразу выводит в левой колонке список файлов, в которых нужная подстрока нашлась. По каждому такому файлу можно щелкнуть мышкой, и он будет показан в правой колонке с выделенными желтым нужными словами (словосочетаниями).
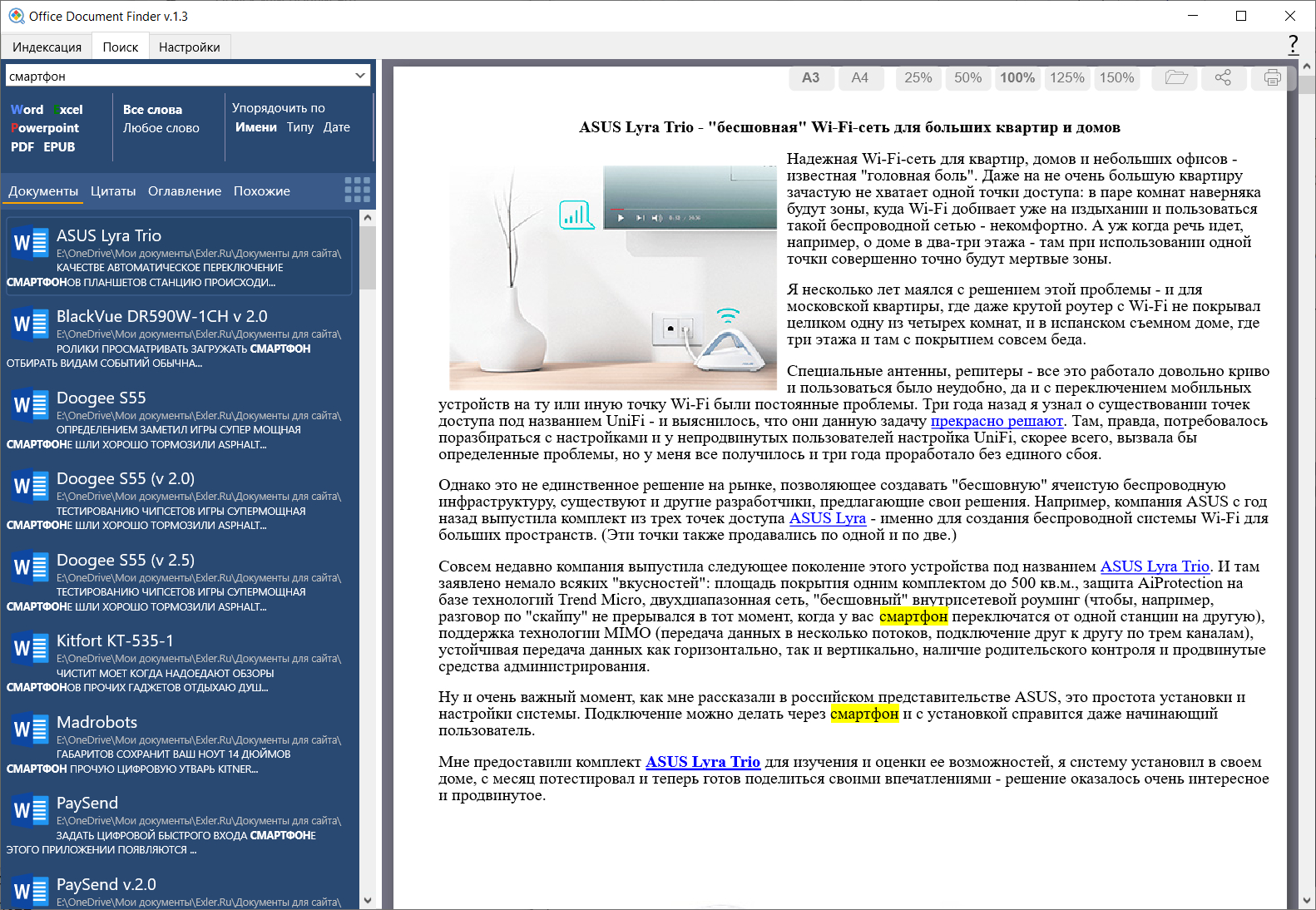
С помощью панели справа сверху можно менять масштаб просмотра, открывать данный файл в соответствующей программе, делиться им или выводить на печать.

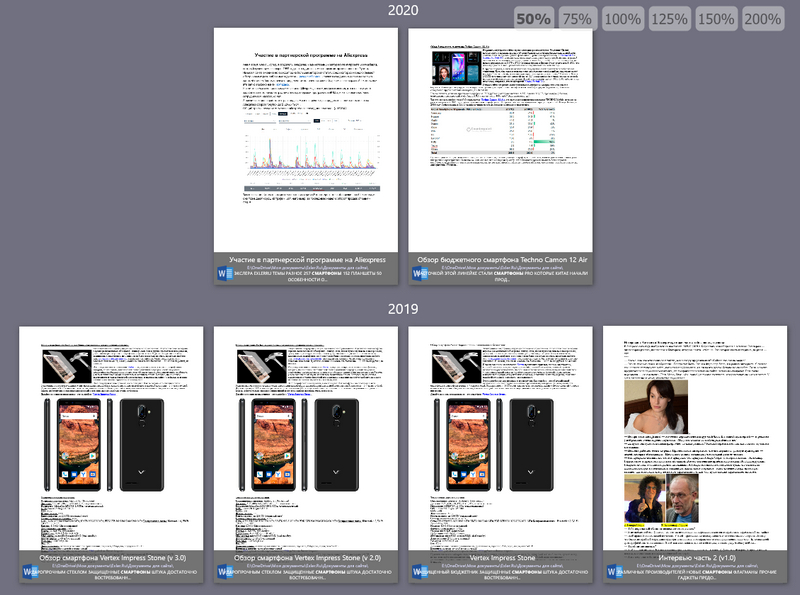
Если переключиться в режим просмотра миниатюр, то это будет выглядеть как-то так (масштаб вы также можете менять).

В режиме просмотра миниатюр при наведении мышки на лист слева сверху появляется пиктограмма, с помощью которой документ можно скрыть из данной выдачи.
Если в настройках включено создание облака тегов, то эти теги будут показываться на миниатюрах предпросмотра.

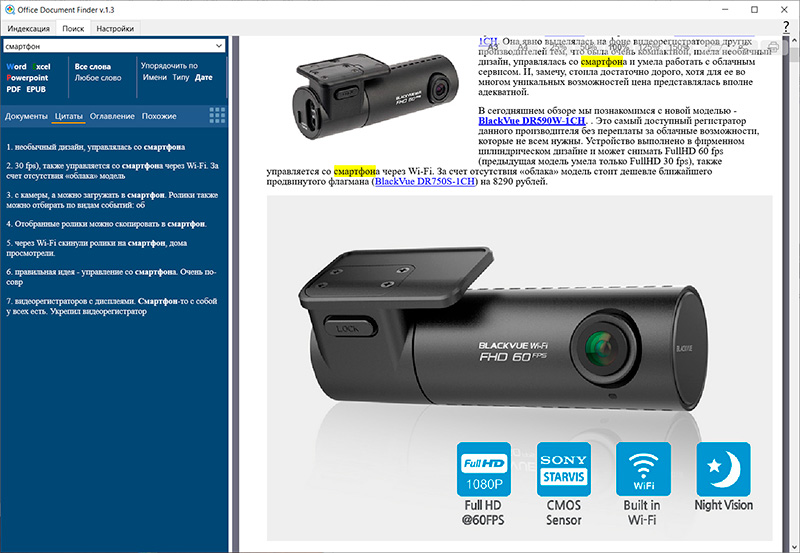
Если из закладки "Документы" перейти в закладку "Цитаты", то там покажут все поисковые вхождения для выделенного документа.

На каждую из них можно нажать, в правом окне будет показан сам документ.
Если рассматриваемый документ имеет оглавление, то его верхний уровень будет показан в разделе "Оглавление".
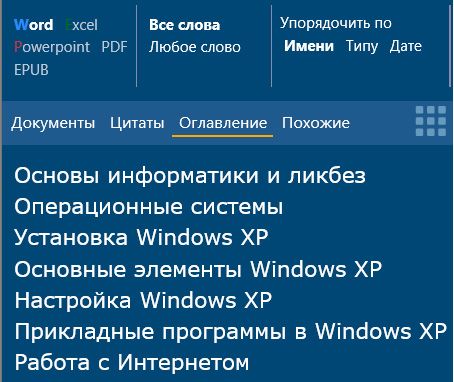
Ну и последняя вкладка - "Похожие". Там показываются документы, которые по ключевым словам аналогичны отобранным документам по поисковой строке. В некоторых случаях это может пригодиться.
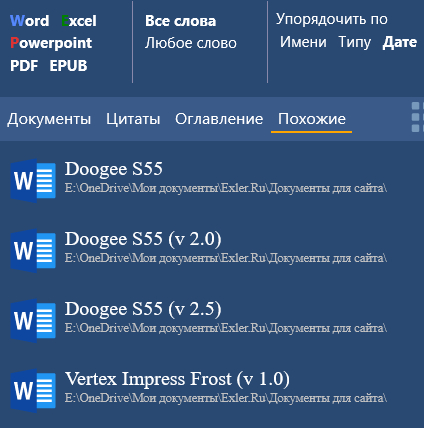
Ну и еще важный момент. Выдачу документов можно сортировать по имени, типу и по дате. При сортировке по дате и в столбце отбора документов их будут группировать по годам и при просмотре миниатюр.
Запросы для поиска могут быть достаточно сложными: здесь используются правила, схожие с используемыми поисковыми системами в Интернете.
При вводе запроса, состоящего из нескольких слов, отображаются документы, в которые входят все или любое из слов в зависимости от выбранной опции поиска. Пример:
договор аренда
Найти документы, содержащие слова "договор" и "аренда" (либо любое из слов, если выбран данный режим).
При поиске также будут найдены документы, включающие слова, начинающиеся с указанных, например: "договора", "арендатор" и так далее. (Данное правило не работает для коротких слов, с которых начинается слишком много других слов, например слово "все".)
Для поиска по точной форме слова оно указывается в кавычках: 'договор'.
Для исключения документов, содержащих определенное слово, оно указывается с минусом:
договор -аренда
найти все документы, содержащие слово "договор" (и его производные), но не содержащие слово "аренда".
Если запрос набран в неверной раскладке, она будет исправлена автоматически. Например, поиск по фразе "Щаашсу Вщсгьуте Аштвук" покажет документы, содержащие "Office Document Finder".
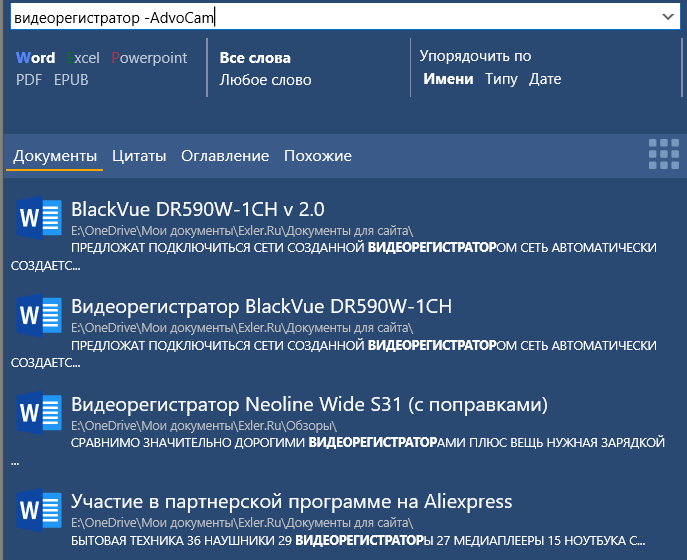
Например, ищем слово "видеорегистратор".

Предположим, нужно исключить все документы с видеорегистратором AdvoCam - задаем запрос: "видеорегистратор -AdvoCam", получаем результат.
С документами PDF Office Document Finder работает так же, как и с другими видами документов, и это очень удобно.
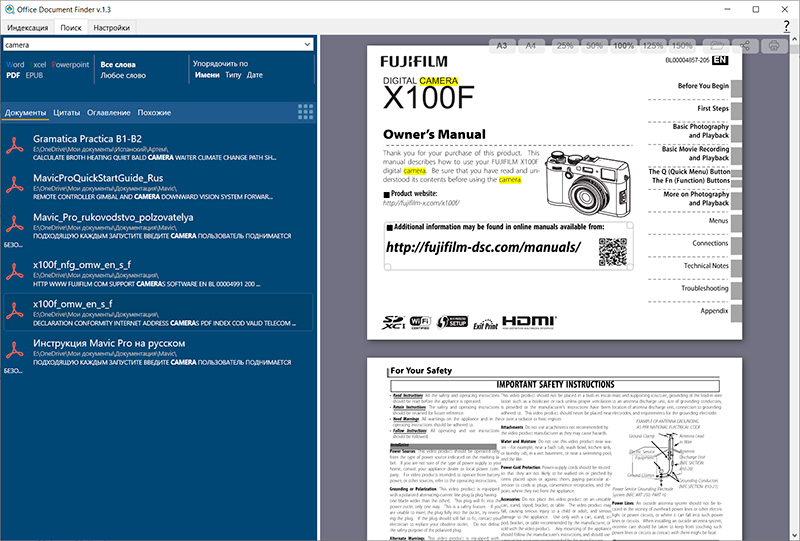
Единственное, если в документе PDF сложная верстка и куча векторных рисунков с мелкими деталями, то могут быть некоторые тормоза с их просмотром. Но такие документы и в Adobe Acrobat тормозят при просмотре.
Работа в браузере
Ссылка на переход в браузер содержится в главном окне программы, однако адрес всегда одинаковый - "http://localhost:50080/" - и на него просто можно поставить закладку в браузере.
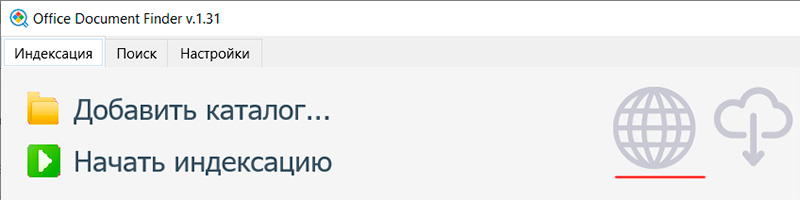
В браузере не добавляются каталоги и не показывается процесс индексации, но оттуда можно осуществлять поиск по документам практически так же, как и в приложении.
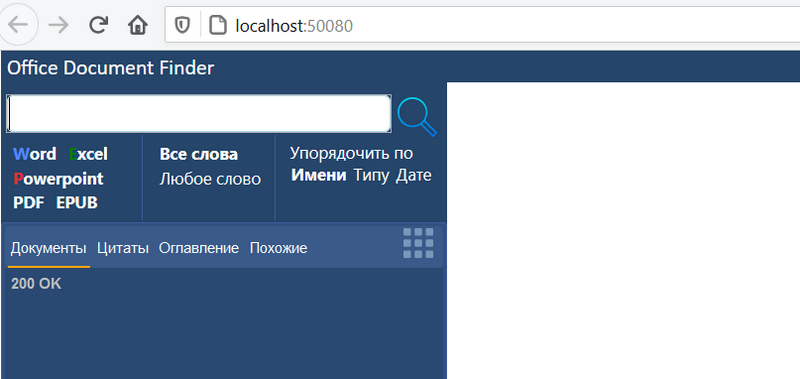
В браузере при вводе поисковой строки выводятся подсказки.
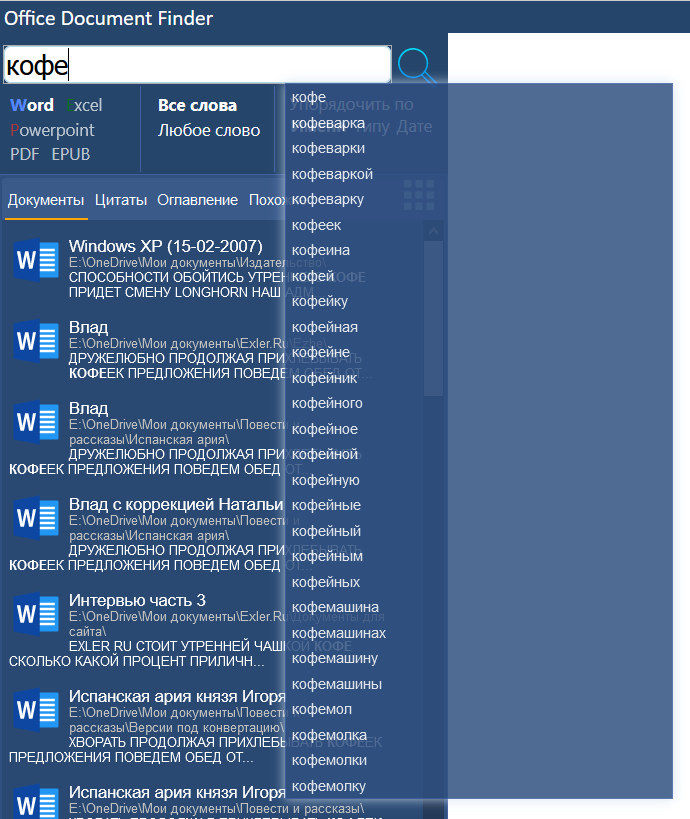
Через браузер поиск и просмотр делаются точно так же, как и в приложении.
Облачный сервис
Еще более интересная возможность - поиск в ваших документах из любой точки земного шара через облачный сервис.
Ссылка на облачный сервис находится рядом со ссылкой на веб-версию в главном окне приложения. Адрес облачного сервиса https://my.officedocumentfinder.com.
При первом переходе на облачный сервис вам предложат создать устойчивый пароль. (Если в дальнейшем пароль нужно будет поменять, то нужно нажать на эту иконку с зажатым Shift.)
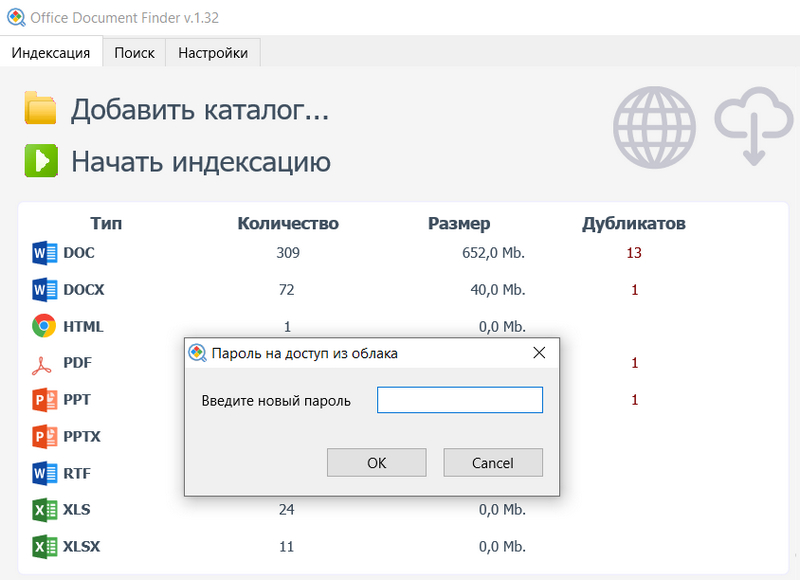
После задания пароля на месте значка облачного сервиса появится QR-код. По нему можно просто щелкнуть мышкой для перехода в поиск по документам через браузер (при этом запросят ввести заданный пароль), также этот код можно отсканировать смартфоном, чтобы зайти в документы со смартфона.

Работа с документами через облачный сервис ничем не отличается от работы с системой через браузер.
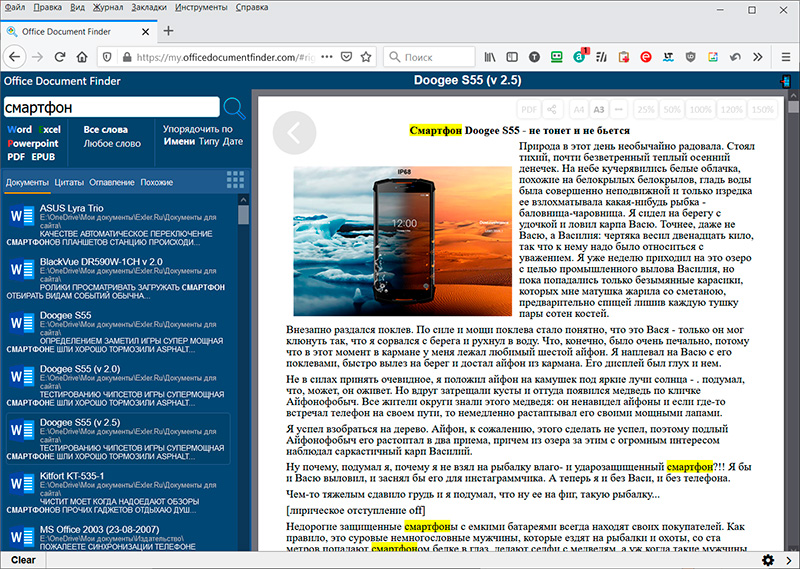
А вот так это выглядит в смартфоне при переходе по ссылке в QR-коде: список документов с найденной поисковой строкой, просмотр конкретного документа.


Тут, конечно, сразу возникают важные вопросы по безопасности: а это что же, получается, что сервис хранит индексы моих документов в облаке?!!
Нет, в облаке не хранятся никакие ваши данные. Поиск по-прежнему происходит на вашем локальном компьютере, а облачный сервис в данном случае выступает в роли прокси, которая дает доступ вам к вашей базе поиска через Сеть. Заданный вами пароль в облако также не передается.
Доступ через облако автоматом не включается, вам нужно щелкнуть по пиктограмме облачного сервиса после запуска программы - только так доступ будет включен. И сам поиск через облако будет работать непосредственно на вашем персональном компьютере.
Публичный доступ к документу
И в приложении, и в браузерной версии к любому документу можно предоставить публичный доступ. Это делается с помощью пиктограммы "Поделиться".

При нажатии на эту пиктограмму система сгенерирует QR-код, который автоматически скопируется в буфер обмена, откуда его можно будет вставить в письмо или сообщение.

При сканировании этого QR-кода адресат получит доступ к просмотру данного документа. Однако у вас при этом на ПК должно быть открыто данное приложение: стоит его закрыть, доступ будет потерян. Кроме того, ссылка действует только один день.
Вот документ, которым поделились, открытый в смартфоне. Он доступен только для просмотра.

Заключение
Мне понравилась эта система, теперь сам ее использую. Удобная, достаточно быстрая, при необходимости можно делать сложные запросы, а результаты сортировать по различным критериям.
Удобно, что есть защищенный доступ через облако без отправки данных в облако и что любым документом можно поделиться для просмотра.
P. S. Если вас эта система заинтересует и вы захотите высказать какие-то свои пожелания в соответствии с вашим возможным сценарием применения Office Document Finder, то напишите об этом в комментариях, разработчики это обязательно прочитают и примут к сведению.




