Адрес для входа в РФ: exler.bar
OCR - распознавание текста в изображениях
Мне периодически нужно распознавать испанский текст на картинках или PDF, также английский и русский. Делать это приходится нечасто, поэтому отдельное приложение для распознавания я не искал: когда понадобилось, просто задал строку в поиске, попробовал первый же попавшийся онлайновый сервис, и так он мне понравился, что ничего другого я искать и не стал.
Сервис называется Free Online OCR, он бесплатный (с определенными ограничениями), поддерживает не один десяток языков, работает и с изображениями, и с PDF, умеет преобразовывать распознанный текст (или файл PDF) в документ Word, документ Excel или в обычный текст. Очень неплохо справляется даже с некачественными картинками и PDF - вот прям рекомендую.
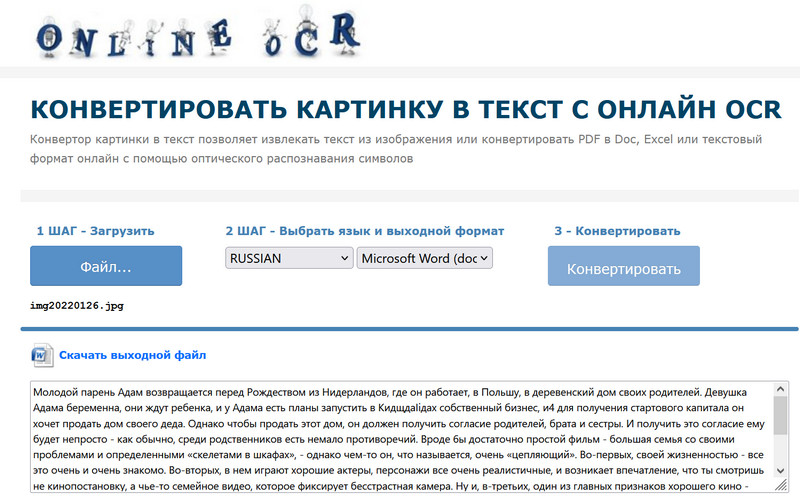
В бесплатной версии разрешается распознавать до 15 страниц в час, максимальное количество страниц в документе - 10, максимальный размер файла - 15 мегабайт. Для подавляющего большинства пользователей этого вполне достаточно.
Ну а теперь вопрос: а вы какими сервисами распознавания пользуетесь? Может, есть что-то поинтереснее?
Чуда не произошло.
Так же как и офлайновые распозналки требует четкой картинки. Двенадцатый финереадер на том же файле отработал заметно лучше.
Чуда не произошло.
Reader только читает, что собственно вытекает из его названия.
Foxit Pro (для pdf) тоже ломаный.
www.ilovepdf.com
FineReader (стаааренький, шел в комплекте со сканером)
OneNote для английских текстов
Для сканов использую на телефоне Adobe Scan и MS Lens
Для скана документов с компа - чудесную софтину iCopy
Для скана картинок - чаще всего FastStone
Вот что меня поразило до глубины души - натыкался на онлайн-сервис распознавания рукописного текста. И когда он довольно корявый почерк распознал на 100% - я прям.... удивился.
Даже например написанные извращенным методом - греческий язык с использованием латиницы - спокойно переводит картинку с такой тарабарщиной
Он для смартфона, но понимает и файлы и можно просто сфотографировать текст.
Всё, дошло... Вот то что у вас на скриншоте - в версии для iPhone называется "Объектив"
А я имел в виду Фотосканер от гугла.
Спасибо...
откройте приложение, наведите камеру на текст, выберите функцию «текст» нажмите кнопку и определитесь, что с этим текстом вы желаете сделать...
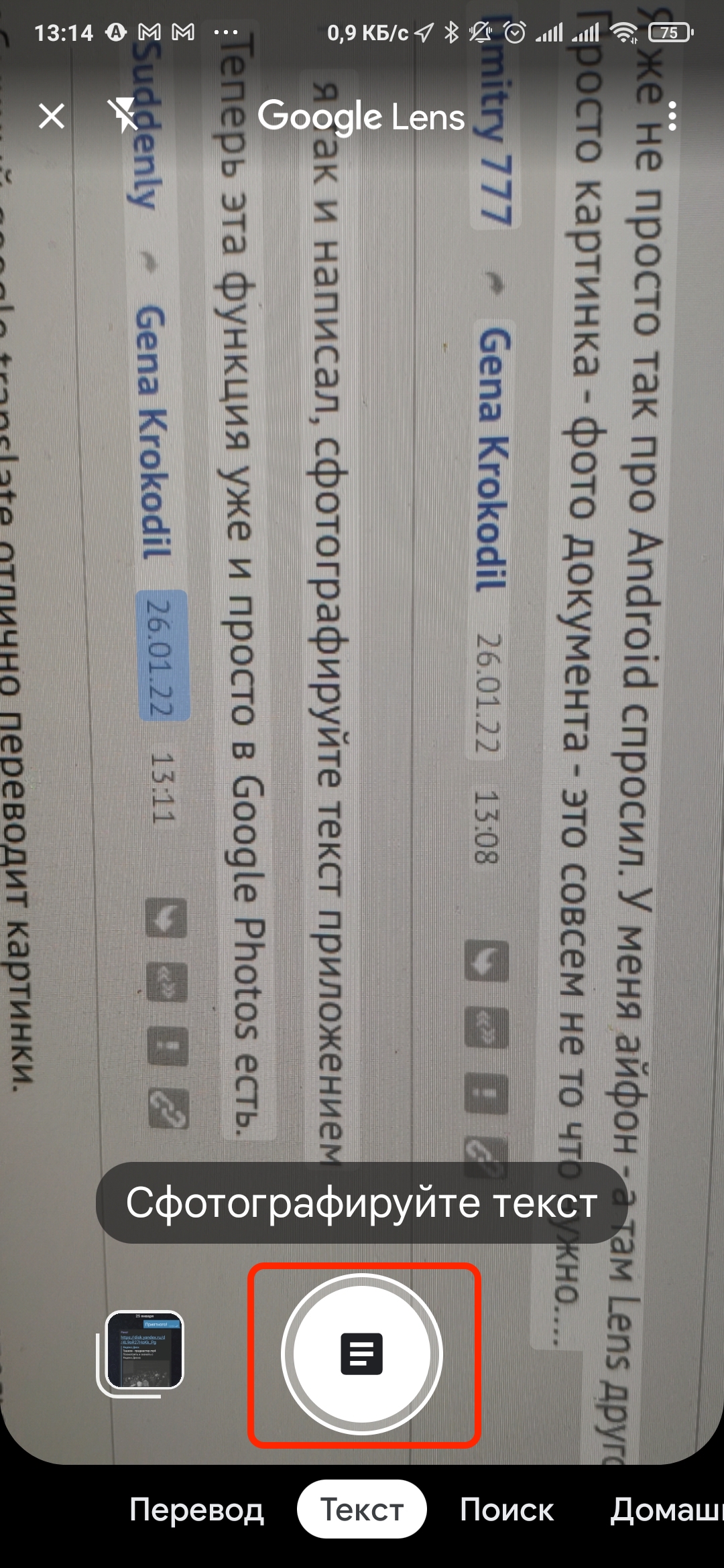
Просто картинка - фото документа - это совсем не то что нужно....
Напомните, кстати - у Google Lens на Андроид есть сканирование именно документов - а не просто картинки?
Также удобен Scanner Mini. Что радует в телефонных приложениях - коррекция геометрии документа. Нет необходимости четко держать кадр на документе, а результат как из-под планшетного сканера. Распознование-ПДФизация (или JPGизация), рассылка почтой и мессенджерами. Что еще надо?
- Сфотать лист текста и сохранить в облако в вордовском формате (важно!)
- открыть документ в ворде на компе - там уже текст распознан и можно пользоваться встроенным вордовским переводчиком
2) камера на айфоне с недавних пор (не понял точно с каких) распознает текст на фотках. Довольно неплохо, но вот по тексту на фотках почему-то поиск не работает. То есть текст прям на фотке можно выделить и скопировать. А найти поиском (что было бы самым логичным применением данной фичи) почему-то фотку с этим текстом нельзя.
И в смартфоне, и на компьютере. Быстро и просто.
И в смартфоне, и на компьютере. Быстро и просто
Бесплатных возможностей хватает.
Очень быстро и удобно делает PDF с уже распознаным текстом.
Можно как камерой страницы фоткать, так и из картинок собрать.
По крайней мере Word из Office 365. Русский и английский текст распознает вполне приемлемо, другие языки не пробовал.
Выделяем прямоугольную область экрана, программа распознает текст и дальше или в буфер, или в ворд, или в эксель. Причем в эксель может сохранять таблицы.
Может сохранить обычный скриншот.
С большими документами не очень удобно работать, а для простой верстки пары страниц очень даже годится.
Стоит около 20 долларов.
capture2text.sourceforge.net
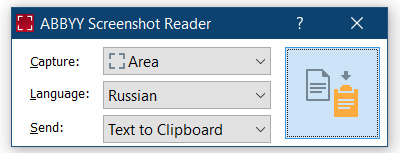
ИМХО, для этого идеально подходит ABBYY Screenshot Reader. Для быстого доступа закрепил его на таскбаре.
Фишка в том, что требуется минимум действий. Нажал кнопку, обвел текст и вуаля -- он в буфере. Не нужно сохранять картинку куда-то или открывать/аплоудить ее куда-то.
PS Привет, коллега ) не так мало времени в 90-х работал в медицинском издательстве от верстальщика-дизайнера до начальника отдела подготовки печатных изданий )
А меньше 200 - да, не рекомендую. По довольно большому опыту обслуживания типографий (был такой штришок в моей биографии)
Т.е. рекоммендуешь меньше 288 не делать? Наш мудацкий корпоративный копир больше 288 не выдает. Так как "вам и не надо".
Пользуюсь официально бесплатной программой, которая работает как сканер (подхватывает всё, в том числе Kyocera, у которого софта нет, только свои дайверы), поддерживает импорт, может немного отредактировать pdf (например, повернуть страницы, удалить) и в том числе распознает текст.
www.naps2.com
Есть портативная версия.
А если нужно распознавать многостраничные pdf, можно воспользоваться вот этим:
data2data.ru